Cite as: Stefanescu, D., 2020. Alternate Means of Digital Design Communication (PhD Thesis). UCL, London.
The main investigation areas presented in the three previous chapters, seen together, sketch and evaluate an alternative to the way digital design information, or data, is being represented, classified and transacted within the AEC industry. Being an applied research project, with heavy input and demands from the industry partners, the software instrumentation developed (Speckle), originally intended purely as support for this research, evolved beyond its intended scope[39]. This is in part due to the technical affordances of the platform, and the communicative processes it enables, but as well due to political factors that normally lie outside a scientific analysis. While the former have been discussed at length in the previous chapters, this section shall now endeavour to tie in both political and technical aspects of the quintessentially wicked problem of digital design communication. As Bruno Latour and other thinkers have shown, scientific pursuit cannot be fully untangled from its social and political context (Harman, 2009; Latour, 2007).
7.1 Schemas and Standards
Chapter 4 questioned what the best way to represent digital design data is in order to support the needed processes of ontological revision that underpin social communication processes. Specifically, the investigation looked at whether an approach based on a composable and incomplete object model can better serve these needs, as opposed to an ontologically complete standard. The results of this investigation (Section 4.3) showed that, if given the possibility and backed by adequate tooling, users will develop their own higher-level digital design ontological definitions in a way that allows them to structure and evolve their communication in a more lean and efficient way—echoing Grice’s maxim of quantity (Grice, 1991), as well as Sperber and Wilson’s relevancy principle by which information tends to follow a path of least “effort” (Wilson and Sperber, 2008). Going even further, Section 4.2 has shown the potential for “backwards compatibility” with existing standards, by programmatically matching the flexibility of a composable lower-level schema with existing object models (BHoM, and, partially, IFC).
The main implication of this result is that, with regards to digital data representation in AEC, the industry has, so far, operated at an inappropriate level of abstraction. If a composable object model approach can offer space for both flexibility as well as consistency, it essentially has all of the advantages and none of the drawbacks when compared with a rigid standard that has the ambition to be ontologically complete.
To unpack the previous statement, one needs to take a wider view of the question of standards. Any communication system will, without a doubt, impose a certain formalised approach. For example, in the case of human communication, this takes the shape of a given alphabet and language, which, in turn are further enriched by a shared social context. In the case of digital communication, due to the unforgiving technical nature of the transmission medium, there are a number of standards that operate at various levels of abstraction, from the low level error correction mechanisms of binary information packets to increasingly more human-understandable layers of information structure and semantics. For example, the internet, as it is known today, is built on top of many layered standards: at the transport level, providing host-to-host communication services, one finds TCP, UDP, QUICK; at the application layer, standardising communication on top of the transport standards above, is where the SSH, FTP, HTTP, SSL/TLS protocols operate. On top of these layers, one finds the technologies that operate at the content level, which describe the human- and machine-readable representational aspects of information (HTML, CSS). Without these standards and protocols—essentially mutually agreed upon conventions—whenever one would want to communicate something digitally, one would need to fall back on 1’s and 0’s and have to re-implement error correction mechanisms from scratch.
The AEC industries have only one such standard, namely the Industry Foundation Classes (IFC). The design ontology described by the IFC standard is one that does not lend itself to modularisation and, subsequently, exchange and revision by actors from the outside. A naive comparison that reveals the scale of the problem is that between IFC and HTML, the markup language that structures all web-based documents. The number of specified HTML standard elements is around 100; the number of IFC elements, at a cursory glance, is higher than 1000. HTML is a low-level standard whose primary expressivity results from its composability and its ability to interact with other systems, purpose-built for different needs[40]: they can be combined in various ways so as to create novel higher-level objects that serve an enormous amount of functions and shape information into meaning both for non-human (machine-readable) and human actors (through rendering). The original set of SpeckleObjects (presented in Section 4.1) was developed with this in mind and aimed at offering a flexible base of CAD “atoms” that could be combined by end users into higher-level logical objects that encapsulate richer meaning.
The findings from Section 4.2.2 have shown that IFC’s complexity translate as well in a large object size, approximatively 12 times larger than other leaner pre-defined schemas. Followingly, this builds a convincing argument towards the fact that IFC, given its sheer size, scope and implementation directives, does not allow or facilitate a communicant to respect Grice's maxim of quantity. In other words, it operates at a much too specific level of abstraction without allowing for improvisation and customisation. Its rigidity leads also to a perceived lack of expressivity: end-users and developers alike are not tempted to experiment with it.
On the other hand, a small and flexible standard lends itself easily to “hacking”. In Section 4.2.3, one of the most striking findings was that one in five base Speckle objects, out of the 16 million analysed, were enriched by end-users, strongly suggesting that this approach was, at least in terms of popularity, well received. Compared to the tree depth of an object derived from a pre-defined schema, end-user generated objects’ hierarchy was mostly flat (an average of 1.97 levels vs. an average of 3.43), thus further supporting an argument against complexity.
Moreover, end-user defined standards can leverage the process of self-contained “emergence” at a higher level of abstraction, as well as become a vehicle for positive network effects outside its original remit by cross-coupling with other technological stacks for different purposes. To illustrate the process of self-contained emergence, several metaphors come to mind. The most naïve, human language, illustrates this: given a finite amount of building blocks (words), a wealth of knowledge and expressivity can be articulated beyond the simple sum of meaning that the words themselves carry. Conway’s famous Game of Life is, perhaps, a better example: given a finite number of states and a finite number of simple rules, the state machine exhibits emergent behaviour (rich interactions that could have not been predicted, or instrumented for).
The latter implication, namely the ability to easily cross-couple with other technological stacks, is extremely relevant in today’s environment. By being understandable and having a manageable cognitive entry barrier, a small composable object model lends itself easily to the digital ambitions of AEC companies. To expand on this, the AEC sector is currently undergoing a “digital transformation”; this has materialised as programmes of “digital transformation” which are specific to each company undergoing one. The needs that arise from these changes put an onerous pressure on how the huge amount of digital design data that these stakeholders produce is used to drive insights from existing projects (that feed back into client and design-facing functions, such as bids) as well as various automation tasks. The source is still design data itself, nevertheless it needs to be ontologically redefined and grouped under various other definitions to serve different purposes. For example, Speckle has been used to drive MEP report generation, embedded carbon calculations, and other automation tasks, all linked with (or based on) original design data. The ontological transformations between the various representations of data (for example, from an architectural definition of a room to a PDF report containing air flow requirements and mechanical equipment provisioning) are not trivial, and required the use of various other technological stacks to process and render. Further research is needed in this area to better identify the various layers of abstraction, their interaction with other technologies, and how the mixture can serve the needs of industry stakeholders in their pursuit for a more integrated digital built environment.
7.2 Classification and Curation
One of the limitations of this “fluid” approach to standards is the potential for data loss. Digital design information, when contextualised in different authoring software, mutates to better fit the available native definitions at hand. For example, a beam can be (1) originally defined as a line with custom properties in Rhino, (2) then become a three-dimensional extrusion with associated parameters in Revit, (3) thereafter morph into an analytical one-dimensional object in a structural analysis package, and finally, (4) a row in an spreadsheet or construction management software. Throughout all these stages, there is no singular object. While at certain stages of this ontological transition process, for example (1) and (3), there are shared geometrical definitions, consistency cannot be guaranteed throughout its whole entirety. This can be traced to the way knowledge is developed and encapsulated in professions: the definition of beam will be different for an architect, a structural engineer or an asset manager. As Abbott would put it, each, when presented with information about a beam, will reshape it to fit the internal standards of their discipline and its body of knowledge (Abbott, 1992).
Consequently, Chapter 5 looked at what is the best way of persisting, or storing, and classifying digital design information for communicative purposes. This was done by mitigating, or managing, the limitation above, as well as by comparing the existing file-based paradigm with an object-centred storage approach. From a technical point of view, Speckle demonstrates that by introducing object fingerprinting and immutability at the storage layer, data loss is avoided. Furthermore, the analysis of the instrumentation and its application in practice within the wider industry network show that a curated, object-centric approach to data exchange is better suited for digital design communication rather than a file-centric approach in which data is shared “in bulk”. These two approaches, rather than excluding each other, can be seen as complementary: the former file-based approach is well suited for design modelling purposes and is deeply rooted in the way AEC authoring software works, while the latter better facilitates data informed dialogue, and allows for the natural evolution of optimal communication channels.
A major implication stems from the fact that, from a technical point of view, both object- and file-based approaches are similar, yet they diverge in the way they can be applied and the nature of the communicative exchanges they foster. At a diagrammatic level, in both a file-centric exchange methodology as well as an object-centric implementation, information storage is centralised. In the former, this amounts to the “one model” strategy, by which all sub-disciplines contribute to, and coordinate with, a unique federated model which acts as a single source of truth. The counter approach is based on a minimal user defined pre-classification, in which objects exist independently of the groups they form; nevertheless, information is still stored centrally within a database. This allows for the sub-classification of a given design into an infinite number of "models" through the mechanism of curating objects into as many groups as needed, based on the criteria that emerge as useful.
The empirical analysis from Section 5.7.3 shows that, in the context of two models, one staged as an example, and one from a real-life project, this leads to important storage savings, which in turn translate to a better ease of use. Subsequently, this leads to an evolving emergence of lean communication channels between the actors involved in the design process, based on based on exchange requirements defined on the fly. These technical nuances, when applied in practice, lead to a divergence in the resulting communicative process: one results in a rigid process that draws clear lines between formal and informal communication links, and discourages the latter; and the other allows for natural communication patterns to emerge and evolve throughout time.
To exemplify, an object-centred approach enables one given design model to be separated into multiple independent classifications for different purposes. One such criteria of classification can be based on functional differentiation of building elements: structure, facade, furnishings, etc.; a different one can be based on the building's levels, namely ground floor, first floor, second floor, etc. It is not possible to pre-determine what the productive categorisation of design data will be for a given project or building; even more, there probably isn’t one singular way of slicing the design information produced during a building project. In this respect, because an object-centred approach provides granular access to individual objects, data can be classified around ad-hoc, arbitrarily defined queries or criteria. These can be defined on the basis of specific stakeholder interests, as they evolve throughout the project. Furthermore, due to design data no longer residing exclusively in traditional files (that needs a specific software in order to be decoded) its outreach, accessibility and transparency is greatly increased. As an illustration, it can be both visualised in a standard browser on mobile devices, tablets and personal computers, as well as imported into widely used tabular software, such as Excel. Moreover, because design data is presented in a self-describing format (JSON) and made accessible through a clear and easy to reason about API, creating new augmented workflows and applications by expert users (or developers) is possible without prior knowledge of the whole system, thus allowing for tailored computational tools catering to tailored needs.
Informational waste is a crucial problem with regards to communication: it ends up being shared without a specific intent, or reason. Thus, in the words of Garfinkel, “noise is introduced in the system“ (Garfinkel and Rawls, 2006), and subsequently leads to higher communicative costs and reduced informational relevance. Countering this trend, the curatorial data sharing methodology introduced in Chapter 5 encourages a certain relevancy check on behalf of the data producers: one is required to have a reason to communicate. Both the recipient and the sender need to collaborate towards and negotiate what data is required of them and for what purposes through dialogue as well as assumption testing of what each other needs are in order to achieve a specific task—therefore the resulting information being exchanged has a specific intent behind it. By ensuring that every “utterance”, or every piece of information that is shared has, to a certain extent, a specific reason for being shared, the risk of creating “disembodied” data (Tsoukas, 1997; Giddens, 1991) is minimised. In other words, data has a given positive effect for the receiver.
The findings in Section 5.7.1 and Section 5.7.2 support the curatorial approach to data exchange described above. Usage data gathered through Speckle revealed that, on average, a single file gives birth to two or more sources of information; similarly, on average, a file can re-combine two different sub-classifications created elsewhere. Overall, they show that data is productively being consumed by end-users—with a source to receiver ratio of 2.26; in other words, for a single emitter, there are, on average, two or more downstream dependencies. One major implication is that, so far, current information exchange practices, based on the federated model as a single source of truth, needlessly impose a technical model of communication (that underpins their software implementations) on what is, in essence, a psycho-social process; the equivalence between how software communication works (Figure 58) and how social communication should be articulated is false.
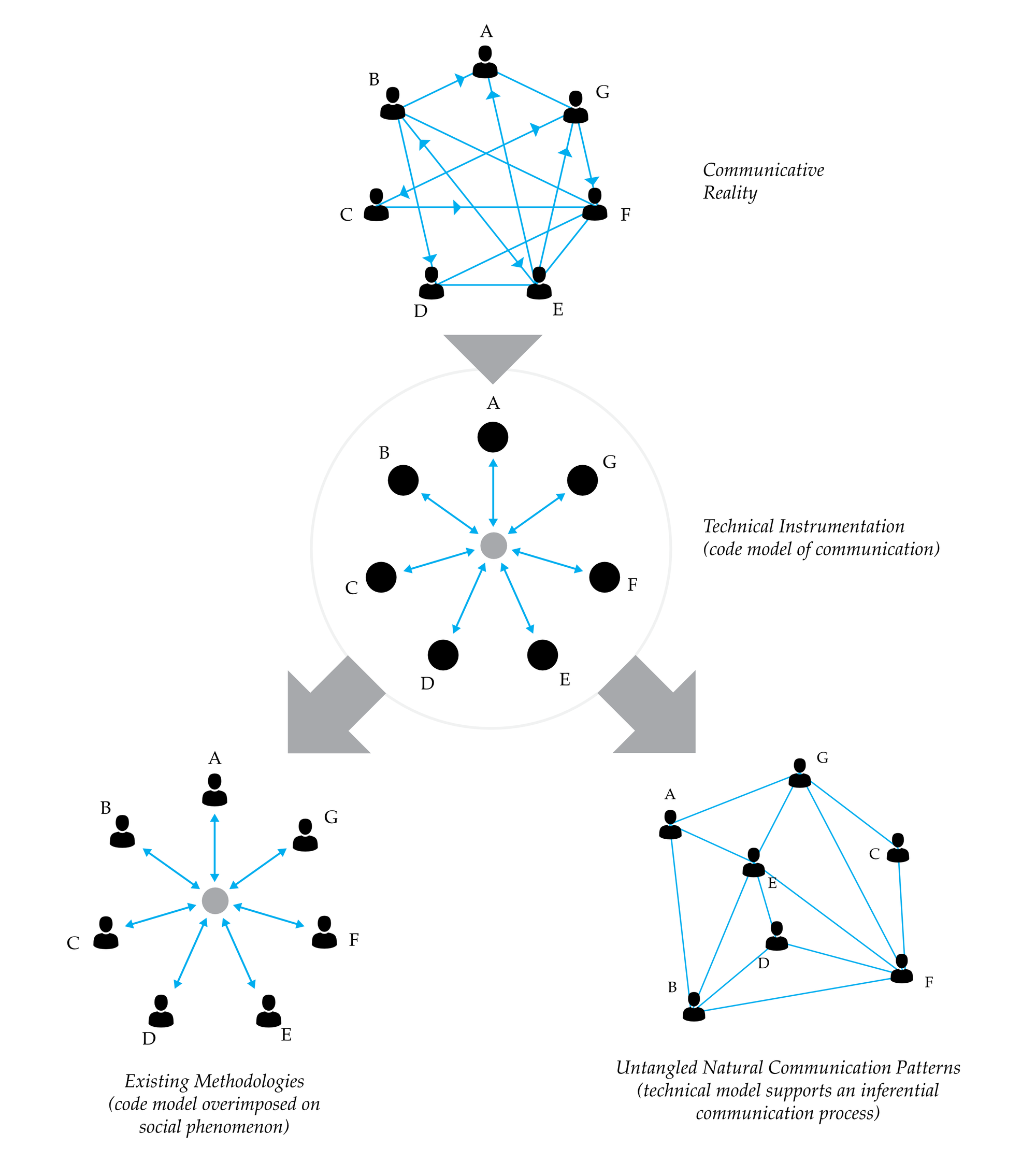
Figure 58: Above: Similar technical code models of communication enabling two different processes in the context of digital design communication. Below: relationship between the communication channels and their supportive (centralised) technical embodiment: multiple users engaged in a digital communication process enabled by one central server.
The picture that the usage data from Speckle painted is one in which end-users assemble their own federated models on a need-by basis, by curating the necessary information for a given task. Subsequently, the clear dividing lines between “formal” and “informal” exchanges, with the latter discouraged from happening, are misguided: formal communication exchanges need to organically evolve from informal ones. Reciprocally, “informal” exchanges should be able to be bootstrapped from existing “formal” ones.
File-based collaboration practices, coupled with current methodologies, enforce formal data exchange patterns, and do not satisfy the need for design data informed dialogue and cooperation; moreover, they act against it by creating disembodied information with decreased relevancy due to lower generation of positive cognitive effects and increased processing effort on the side of the receiver. Nevertheless, the technical, centralised, model of digital communication can be made to support a naturally evolving process of informational exchange which, in turn, allows for the creation of shared understanding and meaning amongst the various actors involved in the design process.
7.3 Digital Transactions & Communication
One of the main limitations with digital dialogue comes from the fact that the medium does not convey the sequentiality of information exchanges: unlike face-to-face conversations, digital data transactions are asynchronous and, often, may happen in parallel between multiple actors. A second limitation pertains to the fact that the actual transaction sizes, especially in a file-based process, can be extremely large and thus compromise another key ingredient of communication, namely nextness, or immediacy.
To elaborate, communicative acts in various professional domains entail different social contracts. In the case of online textual exchanges between people, this difference manifests itself as a demarcation between informal (such as Messenger, WhatsApp, etc.) and workplace (or business) chat applications, such as Slack. The former allows for quick “banter”-like dialogue to happen, and attempts to enrich the digital conversation with various ways of expressing human emotion; the latter, while still allowing for a certain conversational playfulness, is geared towards organising discussions around assignments and topics, creating a conversation record that can be audited, and allowing for various digital documents to be exchanged between users—essentially, attempting to enhance productivity. In the case of collaborative programming, the digital platforms that emerged have different mechanisms supporting a productive workflow. For example, git (and Github, an online collaboration platform based on git), positions itself as version control systems that allow multiple persons to edit files (usually code) in distributed, non-linear workflows. Other platforms, geared towards project management and document-based collaboration, emphasise scheduling features, client interaction management, etc. Nevertheless, in the context of digital design, current file-centric collaboration methods introduce two problems. First, because of their technical foundation relying on sharing models in their entirety, data exchanges are slow and, consequently, far spread apart, thus compromising their nextness. Secondly, because the information being shared is detached from its source, and author, the interdependency between the exchanges is lost. This compromises another key aspect of (social) communicative contracts, namely that of sequentiality.
Chapter 6 shows how these limitations can be partially mitigated. With regards to nextness, by introducing a differential compression algorithm, the size of transactions for both receiver and sender is minimised by transmitting only the changes between updates. Compared to a file-based collaboration process, the analysis in Section 6.2.2 shows that the size of transactions is greatly reduced, with observed performance being twice as high (from the point of view of amount of transacted data, and associated time). As discussed in Section 6.2.3, where the theoretical limit of this approach was examined, a file-based approach performs, regardless of the nature of the change, in a worst-case scenario, whereas differential updates can be situated along a gradient spanning from a worst-case (equivalent to existing methods) to a best-case scenario in which there is no upper bound (if the change is small enough in comparison to the whole). Keeping transactions “as close” to each other as possible allows for a much higher frequency of digital exchanges between communicants.
Section 6.3 describes how sequentiality is (re-)established by tracking the interdependency of the communicative exchanges between the participating stakeholders. This is achieved by grouping together the data, its source software application and originating file, and its owner in what de Vries calls an activity network diagram (de Vries, 1995; de Vries and Somers, 1995).
The case studies presented have shown that exposing this network for each individual data source was successful in giving design stakeholders a more grounded view of the communicative process they are playing a part in, especially for persons involved on specific sub-tasks of a project. Nevertheless, the case studies also showed the need for a holistic overview that would allow, for example, a project manager to carry out his coordination duties that a larger assignment require. In this regard, tracking individual sources of data was not enough. However, the data produced by the proposed implementation is sufficient to recreate an activity network diagram. As part of an InnovateUK grant, research is currently being undertaken on the best way to expose the communicative network in a meaningful manner to end-users. This includes investigations on how to best group, categorise and explore it: around end-users and their roles, around files and applications (Figure 59), around a historical timeline (Figure 60), etc.
Furthermore, while the descriptive nature of visualising sequentiality in a digital communication process is important, its normative potential is also evident: industry feedback, as well as previous scholarly work from the field of product & process management, suggest that an activity network diagram could be created in advance, and then enacted during the design process—a reversed approach to its original goal, nevertheless useful for bootstrapping a known process.
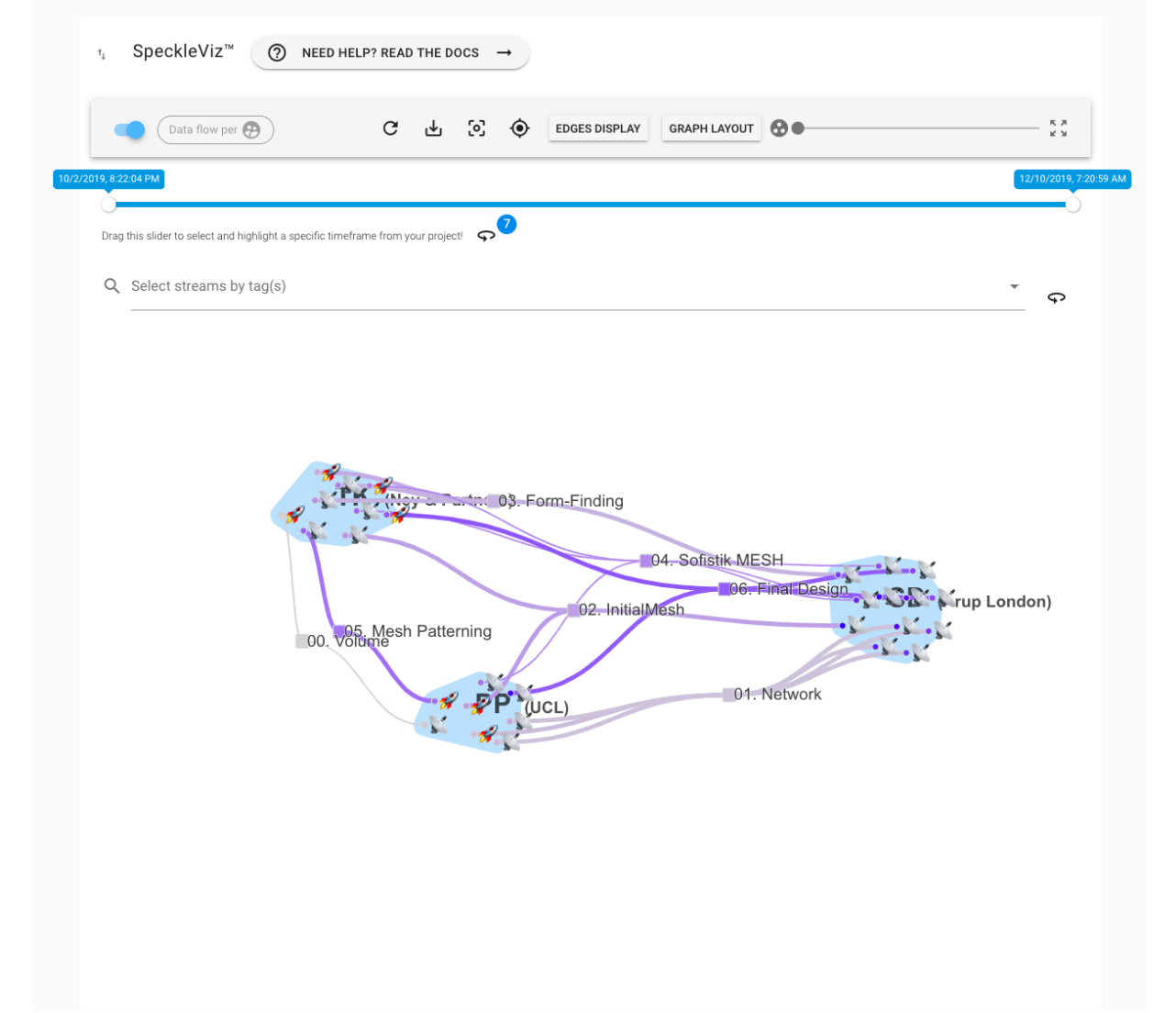
Figure 59: Activity network graph generated for a set of data streams from a live project. Image credits: Paul Poinet, research done at UCL BCPM under the AEC Deltas InnovateUK grant.
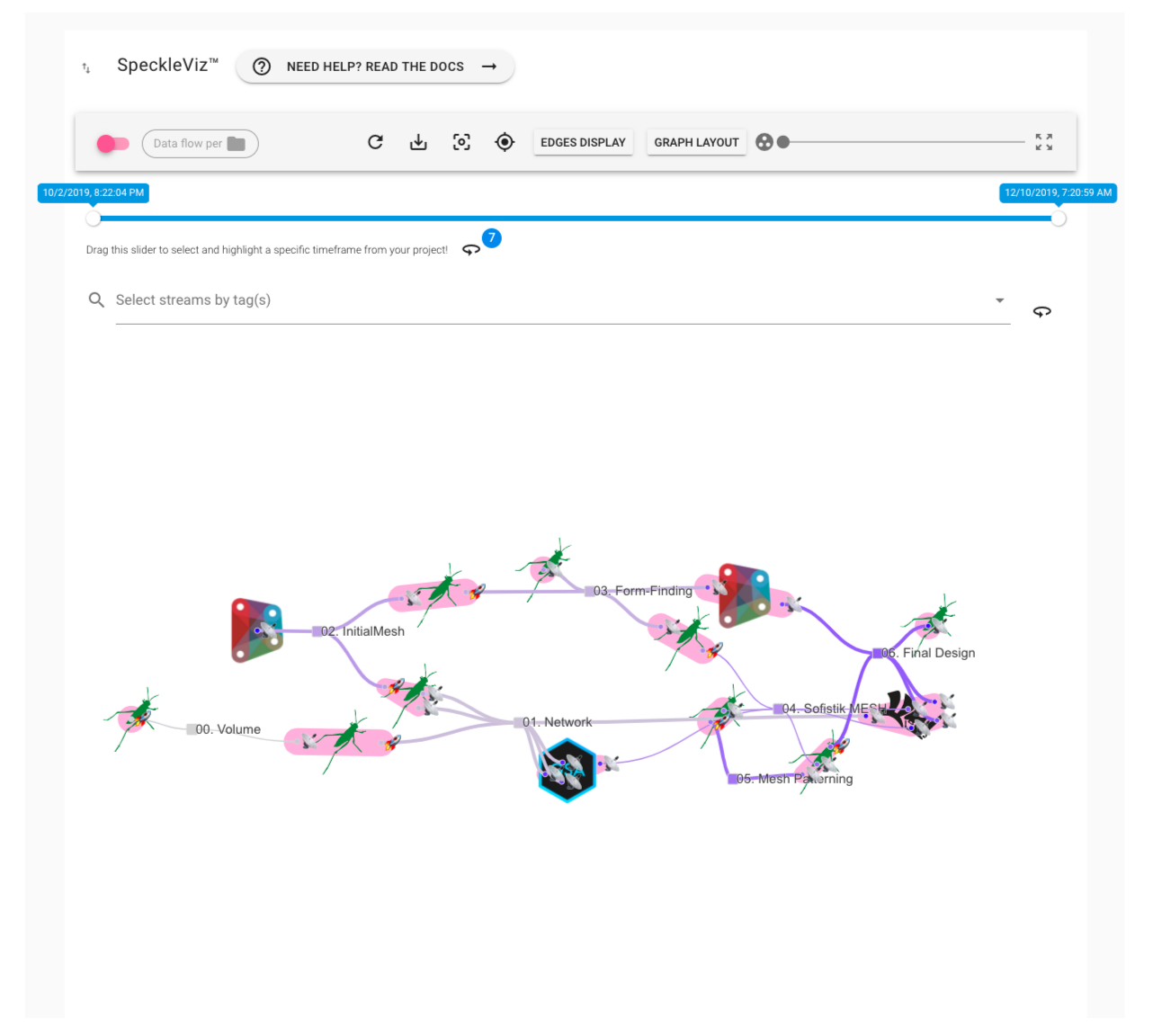
Figure 60: Different activity network, with icons symbolising different software. Image credits: Paul Poinet, research done at UCL BCPM under the AEC Deltas InnovateUK grant.
Furthermore, it is important to note that, while tracking information flow and communicative digital exchanges captures a big part of the design processes, the AEC industry deals with, equally important, processes of material flows. In the context of construction, site planning, assembly, casting, etc. represent equally important dynamic aspects that need to be taken into account.
Summing up, the analysis in Chapter 6 on transactional requirements of digital communication in the AEC industries was restricted to just two fundamental aspects, nextness and sequentiality. Nevertheless, these are not the only aspects shaping it. Further research is needed to understand users’ interactions with such a system, as well as the communicative topologies that emerge, and finally, identify the all the relevant informational and material flows.
In summary, both nextness and sequentiality can be enforced (or enabled) in a digital design environment. These transactional requirements of communicative acts have been so far largely ignored in current tooling. Their inadequate implementation has shaped a slow-paced context of data exchange that is not conductive for the way actual design tasks are being resolved: the frequency of data transactions is directly linked to efficiency of communication, especially in cross-disciplinary environments. Nevertheless, the limitations coming from digital design tasks—large datasets, diverse and spread out teams, etc.—can be mitigated by reducing data transaction costs and keeping information attached to its author and source, thus allowing for the natural emergence of nextness and sequentiality among the data exchanges between the stakeholders involved in the design process.
7.4 Data Ownership
Going beyond the theoretical and technical analysis presented in this thesis, the instrumentation developed to support this research has, through its exposure and adoption in the industry, revealed a strong political dimension of the wicked problem of digital design communication. Specifically, this problem revolves around data ownership and, to a lesser extent, accountability and transparency of the software used. Speckle has been developed and released from the start as an open source project licensed under the liberal MIT license, and all source code is freely available online together with its historical evolution (see Appendix A, Tooling). Unlike other commercially available solutions, users are always in control of where their data resides, and they retain full rights to it.
Data ownership has always been a contentious issue in the digital age. Nevertheless, in recent times, it has come to the forefront of wider public attention due to several events, such as the scandals revolving around mis-use of user information by Facebook, the new EU regulations around data privacy (GDPR), etc. Within AEC, projects usually come with complex requirements around data ownership, safety and various other confidentiality agreements. Existing software vendors that service the AEC industry are thus finding themselves in a conflicting position. Their commercial interests dictate that they do not relinquish control of the wealth of data being produced during the design process; interoperability is a direct threat to the ecosystem of tools that they have built and that drive their revenue. Moreover, new commercial ventures that have attempted (and are attempting) to cater to the interoperability needs of the industry must, by virtue of business common-sense, stay in control of their users’ data in order to charge for it.
Furthermore, the problem is compounded by the fact that current “formal” methodologies—sometimes enforced via governmental mandates, as in the case of the United Kingdom—are adding an extra layer of complexity. The result is an industry where data flows are stifled, and thus the benefits of digital transformation are reduced. Nevertheless, Speckle was written from the start with accessibility in mind, both at an end-user level, but as well at a technical, deployment level. At the deployment level, this translates into the fact that users are encouraged to deploy their own instances of the Speckle server based on their particular needs: at the time of writing, there are more than 40 Speckle servers in operation world-wide.
Industry feedback, informally collated from the living laboratory, reveals several deployment scenarios: (1) internal, local deployments, (2) company-wide regional deployments, and (3) as a global service. Internal deployments (1) are usually described by instances of a Speckle server running locally behind a company firewall. They are not accessible from the outside world, nevertheless designers, engineers and project managers can rely on them for their day-to-day work and they guarantee full data ownership and safety. Company-wide deployments (2) usually run on a cloud provider in the company’s geographical region, and are open to the wider Internet. This allows for interaction with clients and external stakeholders, and they bypass issues arising from latency by their geographic co-location with the majority of their users. Finally, global services (3) are a multi-tenant scenario, in which more companies use the same server, provided and catered for by an external provider, such as a BIM consultancy.
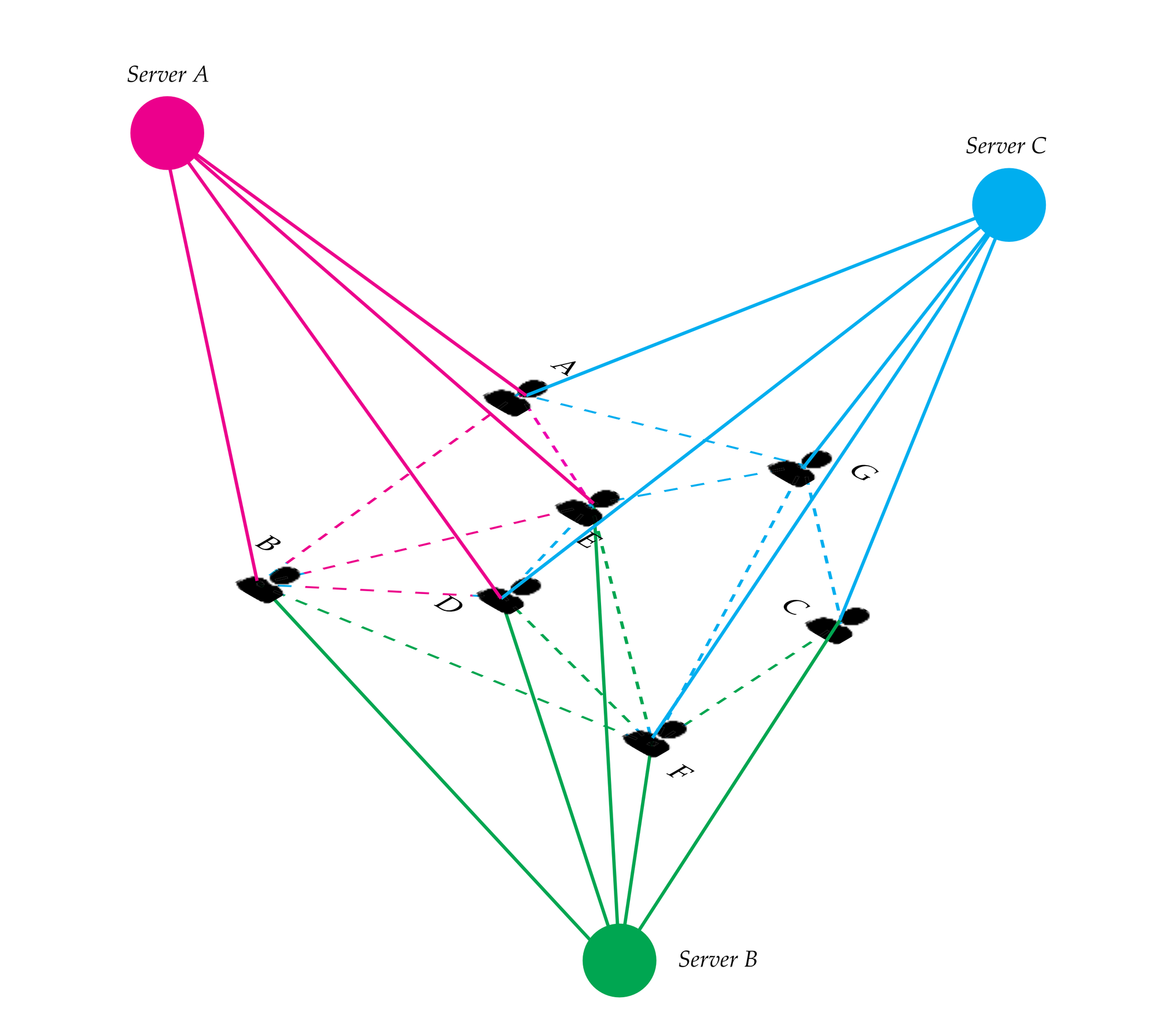
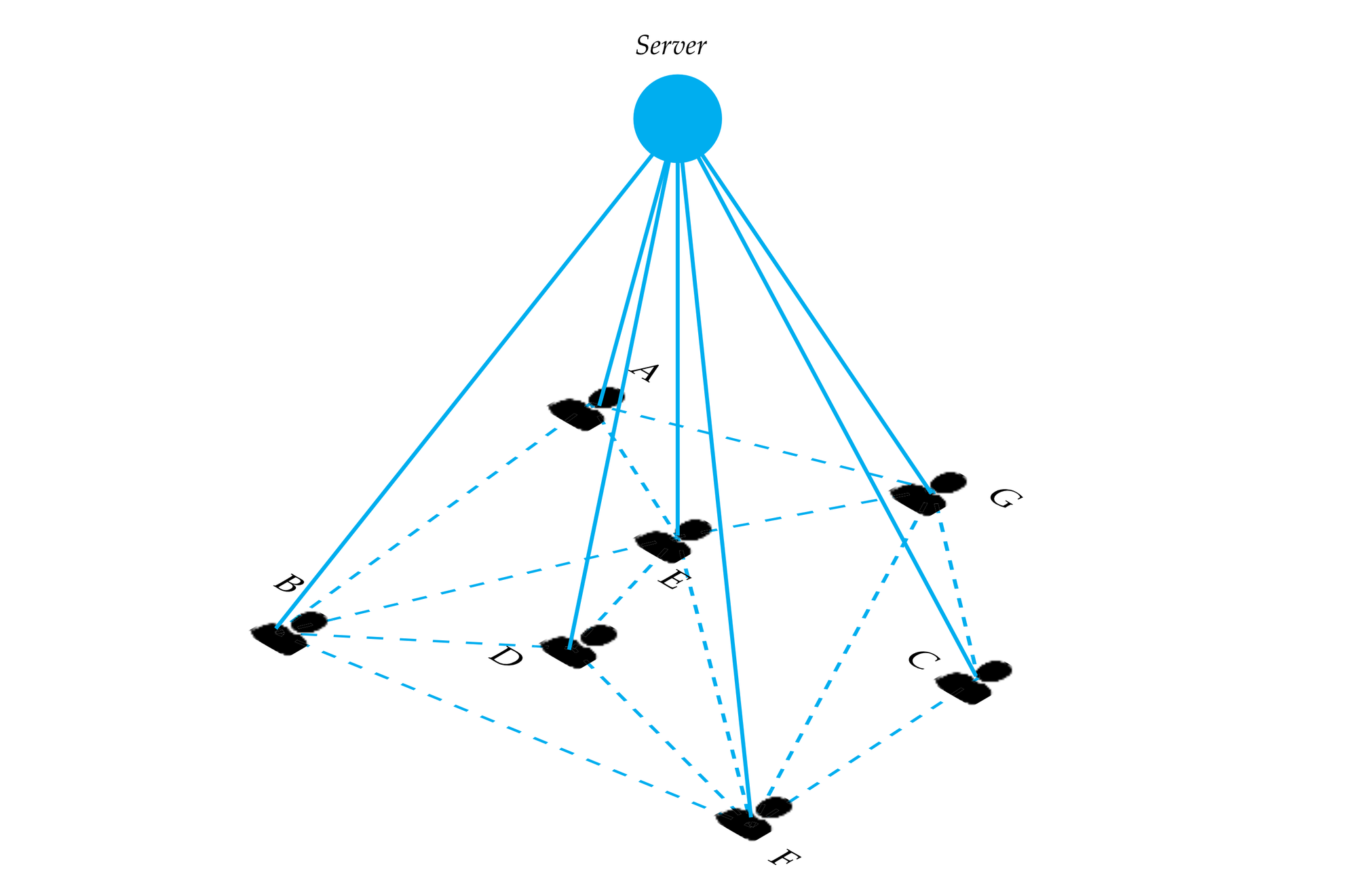
Figure 61: Multi-server communicative network scenario.
At a larger scale, these individual deployments give birth to a decentralised model of data exchange (Figure 61). To clarify, within one server data is centralised, nevertheless, end-users may have accounts on multiple servers, from different parties or companies. Thus, they act as bridges between different, decentralised data sources. Data residency and access is decided organically, based on needs, and each stakeholder has control over what parts are exposed to outside collaborators.
Summing up, design information ownership and access can be situated and managed organically around stakeholders and Speckle deployments and, in turn, selectively opened up based on needs arising from the collaborative requirements of each individual design task. This opens up and enables new avenues for looking at the social and information architecture of collaboration in design projects—simple or complex; avenues which go beyond the current single-source-of-truth methodologies and lead towards better supporting human collaboration and cooperation.
Footnotes
[39] At the time of writing, Speckle continues to evolve and grow its community of contributors and adopters.
[40] Visual appearance (styling) is controlled primarily via CSS; interactivity and real time logic is provided through JavaScript.